On the final day my Learning Perl class, I talk about Zipf’s Law because people now have enough Perl to read a large file, break it up into words, count those words, and sort them by their count.
The final piece of Perl involves sorting a hash by value, which we cover late in the book:
foreach ( @words ) {
$Count{$_}++;
}
foreach ( sort { $Count{$b} <=> $Count{$a} } keys %Count ) {
printf "%d %s\n", $Count{$_}, $_;
}
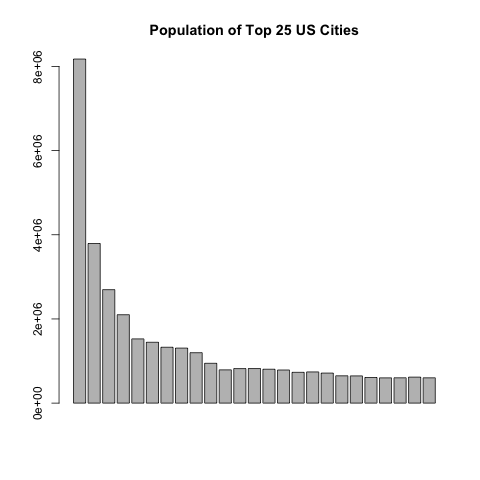
Zipf’s Law states the frequency of things have a power law relationship. The most frequent thing is twice as big as the second biggest thing and three times as large as the third most frequent thing. It doesn’t matter what the thing is. A mysterious law that predicts the size of the world’s biggest cities has a good discussion of it.
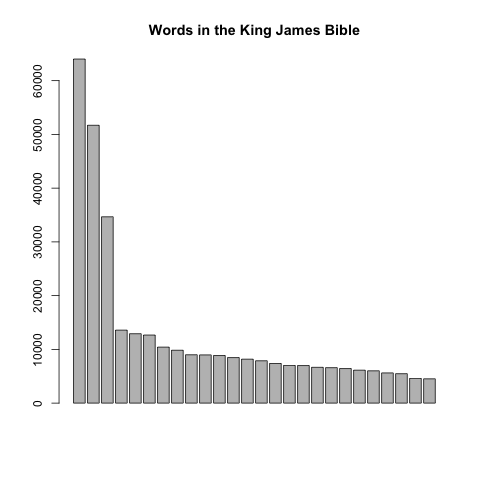
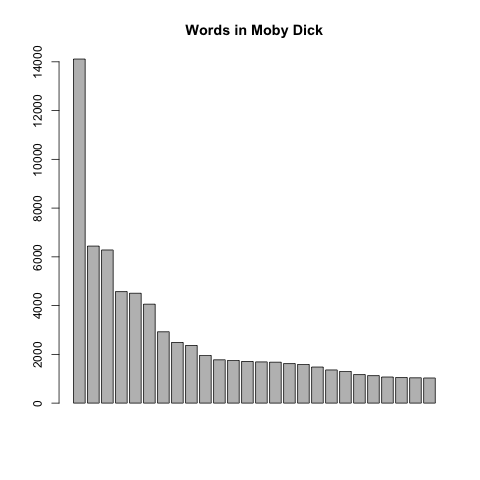
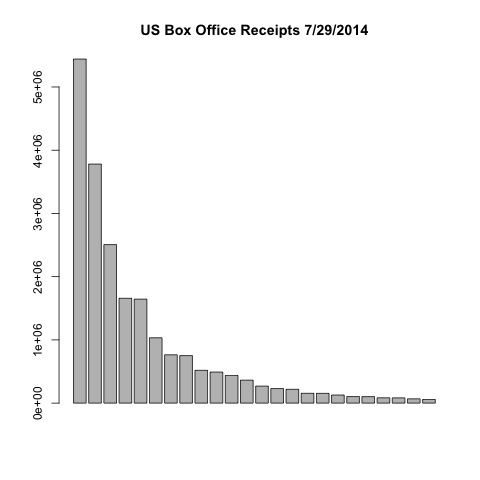
Here are a few plots where I’ve removed the labels and the scale. Each is a different topic.
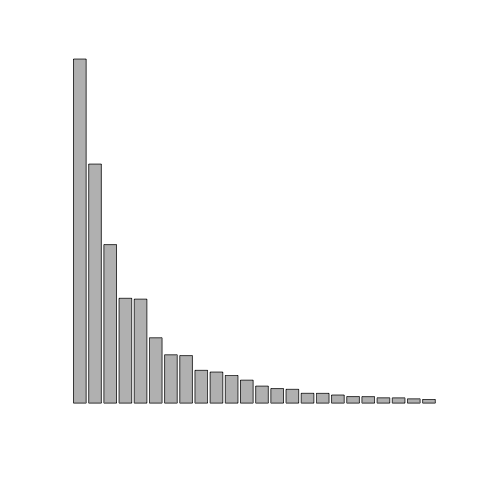
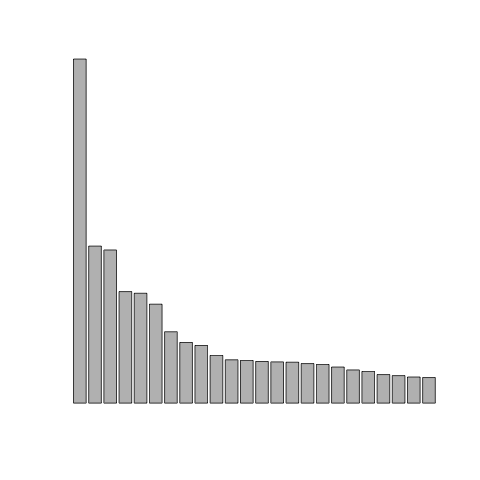
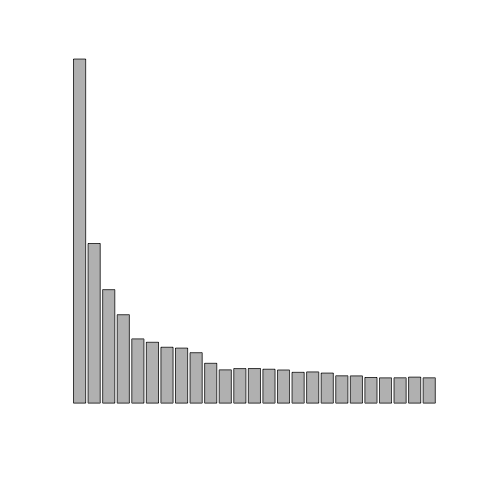
To illustrate this in class, I use the King James Bible and Moby Dick, two out-of-copyright texts I downloaded from Project Gutenburg. I have edited versions that removed the headers and footers (King James Bible and Moby Dick).
I use a simple program (limited to what we show in Learning Perl) to compile the frequencies:
use v5.14;
use List::Util qw(max);
LINE: while( <> ) {
chomp;
$_ = lc $_;
s/\p{Punct}/ /; # unsophisticated
WORD: foreach ( split ) {
next unless /[a-z]/;
my $normalized = s/\P{Letter}//gr; # also unsophisticated
$Count{$normalized}++;
}
}
my $max = max( values %Count );
my $width = length $max;
print STDERR "Max is $max\n";
printf STDERR "There are %d words\n", scalar keys %Count;
print "Count\tWord";
foreach my $key ( so t { $Count{$b} <=> $Count{$a} } keys %Count ) {
printf "%${width}d\t%s\n", $Count{$key}, $key;
last if $displayed++ > 24;
}
Here are the results for those two books:
The other unlabeled plot I showed at the beginning was the US box office receipts for the day I wrote this article:
And, a bonus plot, with the population of major US cities: